Create LinkTable For Fact
Tables of Different Grains
If fact tables have different grains, we need to create a linktable to
remove synthetic key and make data modeling to be star schema.
Step:
1. Create composite key in
each fact table that will associate the rows in the fact table to the
linktable.
2. Use concatenate or join to
create linktable
3. Drop the key fields that
have been added to the linktable from the fact tables
Example:
Sales:
LOAD
AutoNumber(Floor(Date)&'-'& Store&'-'& Product,'Composite_Key1') As Composite_Key1,
[Store],
Product,
Quantity,
Date,
Time,
Amount
FROM
E:\Source\Sales.txt
(txt, codepage is 936, embedded labels, delimiter is ',', msq);
Budget:
LOAD AutoNumber(Floor(Date)&'-'& Store&'-'& Product,'Composite_Key1') As Composite_Key1,
[Store],
Product,
Date,
Budget
FROM
E:\Source\Budget.txt
(txt, codepage is 936, embedded labels, delimiter is ',', msq);
LinkTable:
Load Distinct Composite_Key1,Store,Date,Product Resident Sales;
Join(LinkTable)
Load Distinct Composite_Key1,Store,Date,Product Resident Sales;
Drop Fields Store,Date,Product From Sales,Budget;
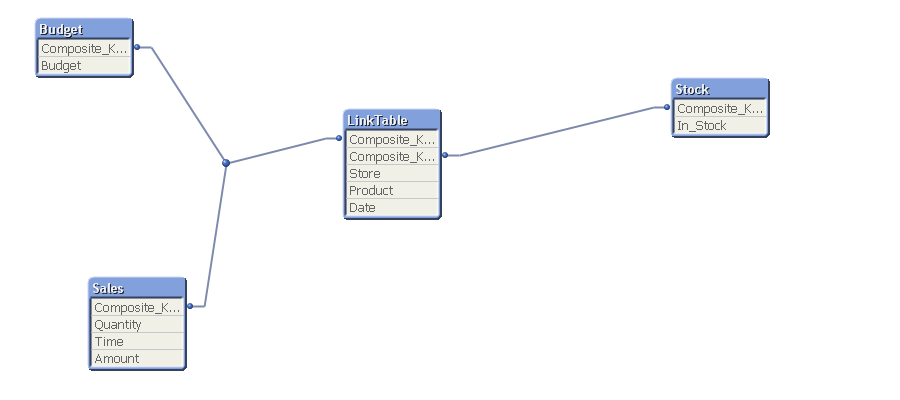
This produced data model like the following:

Stock:
Load AutoNumber(Store&'-'&Product,'Composite_Key2') As Composite_Key2,
[Store],
Product,
In_Stock
FROM
E:\Source\Stock.txt
(txt, codepage is 936, embedded labels, delimiter is ',', msq);
Join(LinkTable)
Load Distinct Composite_Key2,Store,Product Resident Stock;
Drop Fields Store,Product From Stock;
the data model looks like the following: